
One of the most compelling movements I currently see is Serverless Architecture. So what is serverless architecture? The most interesting definition is not technical, but rather comes when looking from a financial perspective.

Typically when we are running a web application, we are billed based on capacity. We buy a couple of big servers that can handle a big load, and use maybe 10% of its power. As IT-people we like it that way, for some good reasons.
- If one of the servers crashes, the other servers should still be able to handle the load.
- Usage is often very peaky. For example, you might use 80% of the power when calculating invoices at the end of the month. The rest of the month our servers are pretty bored.
- Adding new hardware or extra storage can take days, so we overestimate the needed capacity. Just to be safe.
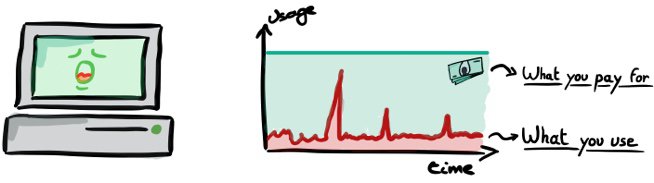
This is all well and good, but if you use only 10% of the power, you are wasting 90% of your money.
Luckily the Cloud saved the day.
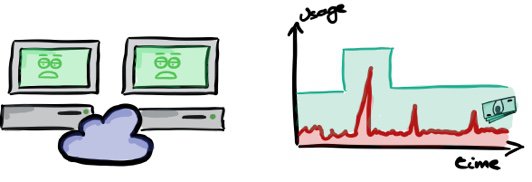
When you move to the cloud, we can quickly and automatically create and destroy (virtual) machines. Increasing storage is just as easy. Our capacity can more closely track the actual usage. There is less waste in this case.
We still leave some room though, not using the capacity fully. Adding a new virtual machine and setting it up might still take a couple of minutes (assuming a mature “devopsed” organisation, otherwise it can still take hours/days). We still need to handle peaks, be prepared for crashes, etc, etc. So we target an average usage of 60% and waste only 40% of our budget.
But what if we could pay based on actual usage instead of capacity?
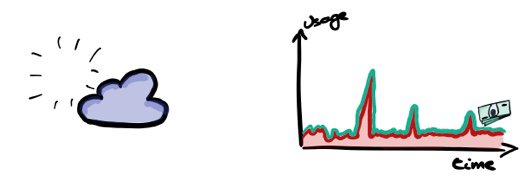
This is what serverless is about. You don’t pay for servers or capacity in general. You pay for actual usage. In their paper Serverless Computing: Economic and Architectural Impact Gojko Adzic and Robert Chatley cover two case studies of moving to a serverless architecture. They calculated a cost reduction of 66% to 95% by adopting serverless. In a next blogpost I will cover the architectural impact and limitations (we still didn’t find that silver bullet).
A lot of the cost reductions also comes from reducing operational costs. We don’t need to buy the hardware or manage the operating system (installing updates, setting up backups, failover,…) These are provided by big cloud providers, who have economies of scale on their side. We can focus on developing and running software.
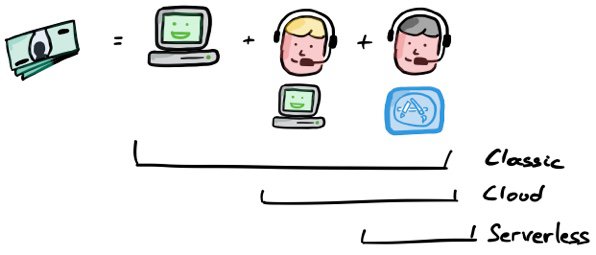
Serverless doesn’t mean there are no servers. The servers are just owned, operated and managed by Amazon, Google or Microsoft. They have built massive capacity and are sharing it accross all their customers. Isn’t that time-sharing? Maybe, but serverless sounds way cooler.
Share this post or follow me on Twitter